
[IT this and that] 자연어 처리 기법과 활용
AI경영연구WG 김동현
SF영화를 보면 인공지능이 사람의 말을 모두 알아듣고 이해하고 행동하는 것을 쉽게 볼 수 있다. 심지어 몇몇 영화에서는 보통 사람보다 더 인간적이고 철학적인 생각을 하는 인공지능 로봇들도 등장한다.
“정말 영화에서 나온 것처럼 인공지능이 사람의 언어와 감정을 모두 이해할 수 있을까? “
인간의 언어는 수천년의 역사를 가지고 다양하게 분화되고 발전해 왔다. 그리고 많은 부분 설명하기 힘든 감정이나 암묵적인 지식들로 구성되어 있기 때문에 정성적인 성질이 강하다. 그래서 정량적 데이터가 필요한 현재의 인공지능 학습 방법으로는 이러한 언어의 요소들을 이해시키기 어렵다.
그러면, SF영화에 나오는 것들은 허황된 이야기일 뿐인 것일까?
꼭 그렇지만은 않다. 우리 주변을 잘 살펴보자. 가장 가깝게 AI 스피커를 발견할 수 있을 것이다. 복잡한 대화는 아직 어렵지만 일상적이고 반복적인 간단한 말 들은 아주 잘 이해 한다.
예를들어 잠자리에 들기 전에 다음과 같은 대화를 할 수 있다.
나: (잠자리에 누우며)”OO야! 나 이제 잘래”
AI 스피커: “알람은 몇 시로 할까요?”
나: “내일 아침 7시에 깨워줘”
AI 스피커: “내일 아침 7시로 알람 설정 되었습니다.”
나: “방에 불 꺼줘”
AI 스피커 : (방에 불을 끄며)”수면에 좋은 음악을 틀어 드리겠습니다.”
(약 30분정도 잔잔한 음악 재생 후 종료됨.)
AI 스피커를 사용하기 전에는 이런 것들을 직접 손으로 해야 했다. 휴대폰에 알림을 맞추고, 잠들기 전에 들을 음악을 리스트에 담고 타이머를 맞춘다. 그러고 나서야 방에 불을 끄고 잠자리에 눕는다. 하지만 이젠 바로 잠자리 누워서 말로만 하면 된다.
“어떻게 가능한 것일까?“
이것을 이해 하기 위해서는 먼저 컴퓨터가 사람의 언어를 이해하기 위해서 시도 되었던 기계번역에 대해서 알아볼 필요가 있다.
초기에는 정해진 규칙에 의해서 번역을 해주는 ‘규칙기반(혹은 중성언어 기반)’으로 언어를 컴퓨터가 다루도록 하였다. 말 그대로 개발자가 정한 규칙에 의해서 원문을 타겟 언어로 번역해 주는 것인데, 앞서 언급한 말로 설명하기 힘든 감정적인 부분과 암묵적인 지식들을 개발자가 모두를 규칙으로 담기에는 한계가 있었다.
이러한 한계를 뛰어 넘기 위해서 나온 것이 ‘말뭉치 기반’으로 번역하는 방식이다. 말뭉치 기반은 크게 ‘예시 기반’과 ‘통계 기반’ 2가지로 나누어 진다.
‘예시 기반’은 원문과 번역문을 저장해 두었다가 똑같은 원문 요청이 왔을때, 이를 활용하는 방식이다. 그리고 ‘통계 기반’은 원문과 번역문의 상관관계 빈도수를 통계화하고 이 수치를 활용하는 방식이다.
말뭉치 기반으로 번역을 하게 되면, 사용을 하면 할 수록 새로운 말뭉치 데이터가 누적 되기 때문에 사람의 개입 없이 컴퓨터가 스스로 언어의 정보를 익히고 처리해준다. 뿐만 아니라 번역 완성도도 점점 높아지게 된다.
“어떻게 말뭉치 기반이라는 것이 앞서 언급한 사람 언어의 정성적인 부분을 상관관계 형태로 통계화 하고 수치로 만든다는 것일까?”
컴퓨터에게 ‘사과’와 ‘배’라는 두 단어를 보여준다면, 단지 유니코드 집합으로 해석 할 뿐 두 단어의 개념적 차이를 이해할 수는 없다.

그러면 유니코드가 아닌 컴퓨터가 이해 할 수 있는 수치를 사용해야 한다. 그것이 바로 벡터로 표현 하는 것이다. 벡터를 만드는 방식 중 하나인 One-Hot 인코딩 방식을 이용하여 간단히 설명해 보면, 다음과 같다.
문장에 의도를 파악하기 위해 필요한 요소가 [왕, 여왕, 남자, 여자]라면 ‘왕’를 표현하는 벡터는 [1, 0, 0, 0]이 되는 것이다. 그리고 ‘여왕’를 표현하는 벡터는 [0, 1, 0, 0]이 된다. 이런 식으로 벡터가 만들어지면 단어들이 실수 공간에 들어오기 때문에 각 단어들의 사이의 유사도를 측정 할 수 있게 된다. 그리고 문장속 단어의 의미 자체가 수치화 되어 있기 때문에 벡터 연산을 통해서 추론을 내릴 수도 있게 된다.
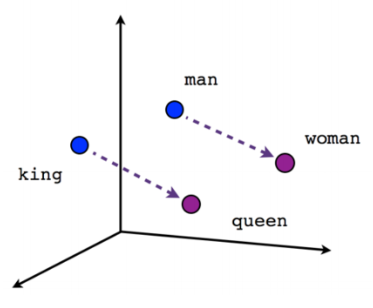 Male – Female
Male – Female
예를 들어 ‘왕(King)’에 대한 벡터에서 ‘남자(Male)’을 빼고 ‘여자(Female)’을 더하면, 벡터 연산을 통해서 ‘여왕(Queen)’이라는 결과를 얻을 수 있게 된다.
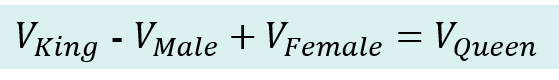 벡터 연산
벡터 연산
이로써 컴퓨터가 사람의 언어적 정보를 단순히 저장하고 읽는 것만 하는 것이 아니라 의도를 파악할 수 있게 된 것이다.
이러한 처리 방식을 통해서 많은 관심을 받게 된 분야가 대표적으로 챗봇있다. 챗봇이 사람의 말의 의도를 파악할 수 있게 되면서 단순한 작업에 대해서 많은 도움을 줄 수 있게 되었다.
최근 가장 성공적인 사례인 ‘코로나-19’ 챗봇을 이야기 해보자.
그 동안의 민원 처리 방식은 모든 민원 내용을 사람이 일일이 읽어보고 취합한 뒤 공지를 통해서 한번에 알리는 방식이 일반적이었다. 이런 경우 민원을 넣고 처리가 되길 기다려야 한다. 질병관리본부에 들어오는 코로나-19에 대한 민원도 마찬가지 였지만 챗봇 도입을 통해서 이러한 문제점에 대해서 많은 어려움을 해소 할 수 있었다.

민원을 하는 사람이 “자가격리자는 어떻게 해야 할까?”라는 질문이 들어오면, 챗봇은 자연어 처리를 통해 사람의 의도를 파악하고 질병관리본부에서 제공하는 생활 수칙 가이드를 찾아서 제공을 해주는 것이다.
해결하고 싶거나 알고 싶은 정보들을 기다리지 않고 챗봇을 통해 바로 안내를 받게 해주면서 사람들 대부분의 민원을 지연없이 해결하게 된 것이다. 그로인해서 질병관리본부의 코로나-19 챗봇 등록자 수가 70만명을 넘어 섰다.
이 뿐만이 아니다. 사용자 층의 챗봇을 바라보는 시선이 전반적으로 달라졌다. 챗봇 초창기에 사람의 말을 제대로 이해하지 못하여서 좋은 사용자 경험을 전달지 못 했다. 그래서 좋은 기능으로 발전했음에도 불구하고 사람들로 부터 외면 받고 있었다. 하지만 코로나-19 챗봇에 대한 좋은 사용자 경험으로 인해서 챗봇이 사용할 만하다는 인식이 생겨 났다.
국내 대표적인 소셜미디어 회사인 카카오와 네이버의 경우 코로나 사태 직전대비 챗봇 사용량이 각각 50%, 18%씩 증가 한 것으로 나타났다.
이는 컴퓨터가 사람의 말을 알아 들을 수 있게 되면서 사용자의 서비스 소비 패러다임이 변하고 있다는 것을 반영한다고 본다. 이러한 페러다임 변화에 대해서 기업들은 많은 관심을 가져야 할 것이다. 챗봇을 통해 기업 비즈니스를 고객들에게 어떻게 서비스 할 것인지 깊게 고민해 볼 필요가 있을 것 같다.