
[IT this and that] 연관 분석(feat. Python)
AI경영연구WG 김동현
지난 포스팅에서 연관분석(Association Analysis)이 무엇인지, 어떻게 결과를 도출하는지 에 대한 이론적인 방법을 살펴보았다. 이제 실제로 연관분석을 Python으로 하나씩 구현해 보자. 분석을 하려면 데이터가 필요하다. 이번 예제에서는 Instacart라는 온라인 기반 농작물 배송 서비스 회사에서 공개한 2017년 9월에 발생한 주문 및 제품 정보에 대한 데이터셋을 다운받아 사용 할 것이다.데이터는 “The Instacart Online Grocery Shopping Dataset 2017” 링크를 통하면 다운 받을 수 있다. 다운받은 데이터는 압축을 푼 후에 작업 폴더에 옮겨둔다. (예제에서는 작업할 Project 폴더에 “./Dataset/Instacart”라는 경로에 데이터를 넣어 두었다.)
먼저, 분석할 데이터를 확인해 보자.
필요한 모듈과 함수, 고정 변수 등을 미리 정의해 둔다. ############ Python Code Strat ############import pandas as pd import numpy as np import sys from itertools import combinations, groupby from collections import Counter from IPython.display import display # 데이터 파일(객체)이 어느정도 사이즈(MB) 인지 확인 하는 함수. def size(obj): return "{0:.2f} MB".format(sys.getsizeof(obj) / (1000 * 1000)) # 파일 저장 경로 path = "./Dataset/Instacart"############ Python Code End ############ Pandas를 이용하여 주문 데이터를 읽어서 데이터의 사이즈와 차원을 확인하고 실제 데이터를 살펴 보기 위해 상위 5개 데이터를 확인해 본다. ############ Python Code Strat ############
orders = pd.read_csv(path + '/order_products__prior.csv') print('orders -- dimensions: {0}; size: {1}'.format(orders.shape, size(orders))) display(orders.head())
orders -- dimensions: (32434489, 4); size: 1037.90 MB
| order_id | product_id | add_to_cart_order | reordered | |
|---|---|---|---|---|
| 0 | 2 | 33120 | 1 | 1 |
| 1 | 2 | 28985 | 2 | 1 |
| 2 | 2 | 9327 | 3 | 0 |
| 3 | 2 | 45918 | 4 | 1 |
| 4 | 2 | 30035 | 5 | 0 |
orders = orders.set_index('order_id')['product_id'].rename('item_id') print('dimensions: {0}; size: {1}; unique_orders: {2}; unique_items: {3}' .format(orders.shape, size(orders), len(orders.index.unique()), len(orders.value_counts())))
dimensions: (32434489,); size: 518.95 MB; unique_orders: 3214874; unique_items: 49677############ Python Code End ############ 차원이 4개에서 1개로 줄었고, 사이즈도 1GB에서 절반정도 줄어든 518MB가 되었다.
데이터가 준비 되었으니, 연관 규칙을 찾기 위한 프로그램(함수)들을 정의해보자.
연관규칙을 찾기 위해서는 지지도, 신뢰도, 향상도 지표를 확인하여 규칙의 효용성을 확인 해야 한다. 이 3개 지표를 계산해 내기 위한 함수를 먼저 정의한다. ############ Python Code Strat ############# 단일 품목이나 품목 집합에 대한 빈도수를 반환한다. def freq(iterable): if type(iterable) == pd.core.series.Series: return iterable.value_counts().rename("freq") else: return pd.Series(Counter(iterable)).rename("freq") # 고유한 주문번호 갯수를 반환한다. def order_count(order_item): return len(set(order_item.index)) # 한번에 한 품목 집합을 생성하는 generator를 반환한다. def get_item_pairs(order_item): order_item = order_item.reset_index().values for order_id, order_object in groupby(order_item, lambda x: x[0]): item_list = [item[1] for item in order_object] for item_pair in combinations(item_list, 2): yield item_pair # 품목에 대한 빈도수와 지지도를 반환한다. def merge_item_stats(item_pairs, item_stats): return (item_pairs .merge(item_stats.rename(columns={'freq': 'freqA', 'support': 'supportA'}), left_on='item_A', right_index=True) .merge(item_stats.rename(columns={'freq': 'freqB', 'support': 'supportB'}), left_on='item_B', right_index=True)) # 품목 이름을 반환한다. def merge_item_name(rules, item_name): columns = ['itemA','itemB','freqAB','supportAB','freqA','supportA','freqB','supportB', 'confidenceAtoB','confidenceBtoA','lift'] rules = (rules .merge(item_name.rename(columns={'item_name': 'itemA'}), left_on='item_A', right_on='item_id') .merge(item_name.rename(columns={'item_name': 'itemB'}), left_on='item_B', right_on='item_id')) return rules[columns]############ Python Code End ############ 다음으로, 실제 규칙을 찾기 위해 위 지표를 구하는 함수들을 이용하여, 연관 규칙을 찾는 함수를 정의 한다. ############ Python Code Start ############
# 미리 준비한 주문 정보(주문번호를 인덱스로 하고 상품번호를 Value로하는 Series)와 최소 지지도를 입력받아 연관 규칙을 반환한다. def association_rules(order_item, min_support): print("Starting order_item: {:22d}".format(len(order_item))) # 빈도수와 지지도를 계산한다. item_stats = freq(order_item).to_frame("freq") item_stats['support'] = item_stats['freq'] / order_count(order_item) * 100 # 최소 지지도를 만족하지 못하는 품목은 제외한다. qualifying_items = item_stats[item_stats['support'] >= min_support].index order_item = order_item[order_item.isin(qualifying_items)] print("Items with support >= {}: {:15d}".format(min_support, len(qualifying_items))) print("Remaining order_item: {:21d}".format(len(order_item))) # 2개 미만의 주문 정보는 제외한다. order_size = freq(order_item.index) qualifying_orders = order_size[order_size >= 2].index order_item = order_item[order_item.index.isin(qualifying_orders)] print("Remaining orders with 2+ items: {:11d}".format(len(qualifying_orders))) print("Remaining order_item: {:21d}".format(len(order_item))) # 빈도수와 지지도를 다시 계산한다. item_stats = freq(order_item).to_frame("freq") item_stats['support'] = item_stats['freq'] / order_count(order_item) * 100 # 품목 집합에 대한 generator를 생성한다. item_pair_gen = get_item_pairs(order_item) # 품목 집합의 빈도수와 지지도를 계산한다. item_pairs = freq(item_pair_gen).to_frame("freqAB") item_pairs['supportAB'] = item_pairs['freqAB'] / len(qualifying_orders) * 100 print("Item pairs: {:31d}".format(len(item_pairs))) # 최소 지지도를 만족하지 못하는 품목 집합을 제외한다. item_pairs = item_pairs[item_pairs['supportAB'] >= min_support] print("Item pairs with support >= {}: {:10d}\n".format(min_support, len(item_pairs))) # 계산된 연관 규칙을 계산된 지표들과 함께 테이블로 만든다. item_pairs = item_pairs.reset_index().rename(columns={'level_0': 'item_A', 'level_1': 'item_B'}) item_pairs = merge_item_stats(item_pairs, item_stats) item_pairs['confidenceAtoB'] = item_pairs['supportAB'] / item_pairs['supportA'] item_pairs['confidenceBtoA'] = item_pairs['supportAB'] / item_pairs['supportB'] item_pairs['lift'] = item_pairs['supportAB'] / (item_pairs['supportA'] * item_pairs['supportB']) # 향상도를 내림차순으로 정렬하여 연관 규칙 결과를 반환한다. return item_pairs.sort_values('lift', ascending=False)############ Python Code End ############ 연관 규칙을 찾기 위한 데이터와 프로그램(함수) 준비가 완료 되었다.
연관규칙을 찾아보자.
############ Python Code Strat ############%%time rules = association_rules(orders, 0.01)
Starting order_item: 32434489 Items with support >= 0.01: 10906 Remaining order_item: 29843570 Remaining orders with 2+ items: 3013325 Remaining order_item: 29662716 Item pairs: 30622410 Item pairs with support >= 0.01: 48751 Wall time: 6min 24s############ Python Code End ############ 출력된 결과를 확인해보자. 약 3천만 건의 주문 정보에서 최소 지지도 0.01를 넘는 약 4만 8천건의 연관 규칙을 찾아 내었고, 연관 규칙을 만들어 내는 데 걸린 시간은 6분 24초가 걸렸다는 것을 알 수 있다.
찾은 결과를 출력해 보자.
############ Python Code Strat ############# 품목 ID를 보기 좋게 하기 위해서 품목 이름으로 바꿔준다. item_name = pd.read_csv(path + '/products.csv') item_name = item_name.rename(columns={'product_id':'item_id', 'product_name':'item_name'}) rules_final = merge_item_name(rules, item_name).sort_values('lift', ascending=False) display(rules_final)
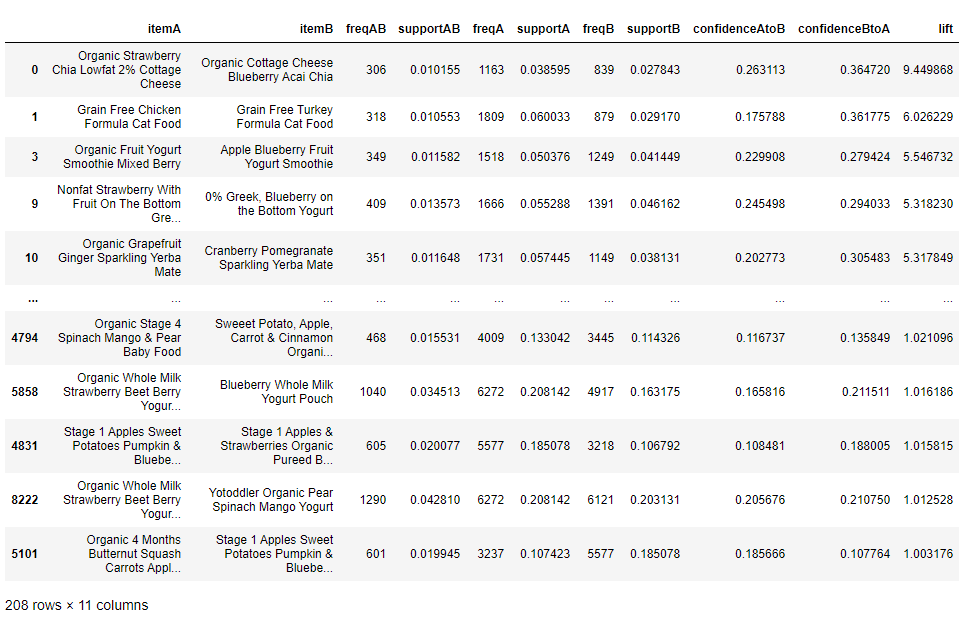
- lift = 1, 품목간의 관계 없다. *예: 우연히, 같이 사게되는 경우
- lift > 1, 품목간의 긍정적인 관계가 있다. *예: 같이 사는 경우
- lift < 1, 품목간의 부정적인 관계가 있다. *예: 같이 사지 않는 경우
출력된 향상도를 이용하여 결과를 분석해보자.
먼저, 품목 간의 긍정적인 관계인 향상도가 1 보다 큰 결과를 살펴 보자.- 코티지 치즈는 블루베리 아사이 맛과 딸기 치아 맛을 같이 구매한다.
- 고양이 먹이는 치킨 맛과 칠면조 맛을 같이 구매한다.
- 요거트는 믹스 베리 맛과 사과 블루베리 맛을 같이 구매한다.
- 유기농 바나나를 사는 경우 일반 바나나는 사지 않는다.
- 일반 품종의 아보카도를 구입한 경우 하스 아보카도를 구입하지 않는다.
- 유기농 딸기를 사는 경우 일반 딸기를 사지 않는다.